Machine learning, the blockchain, they all sound familiar to the majority of people in the analytic world. For people who worked on large-scale machine learning model development and deployment integration, we all know that keep tracking of all the configuration files, raw data, clean data, model objects, model output can be hairy. Especially when you want to roll back a model couple of months later. Even with Bitbucket of Github, there are still many loop areas due to the various working environment.
To illustrate this problem, first, let’s look at the standard machine learning pipeline.
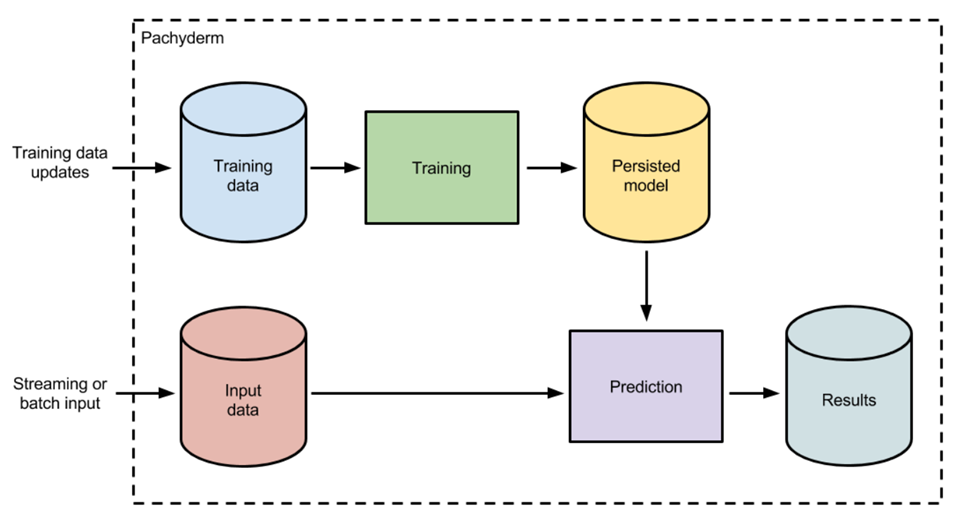
There are two routes for developing and deploying the machine learning model: 1. Training the model and get a persisted model; 2. Apply the model to production batch or streaming input. Typically, these two processes might share the same configuration files for data cleaning, transformation etc. All looks clear here. But here is the catch: imaging you have various people working on the same projects with their code on the local laptop or remote server (version controlled by the Bitbucket). Each person builds a model with some changes to their configuration and at the end of the day, a champion model was selected and the persisted model was copied/moved to the production server. A couple of weeks later, another batch of models was created by working out of the previous champion branch. New versions of codes, configuration, and model objects were created and pushed to the server. Either manually or synced somehow. You might think all the process will work and the configuration files will match perfectly with the persisted model. But it always fails due to failure to git add/push the correct config file, accidentally overwrite the model objects etc. All these nuances will end up having not the best model in production.
How do we solve this problem?
Now I have come up with a solution by borrowing the blockchain transaction verification process. Here is how it works (see image below):
